The Increasing Role of Natural Language Processing
and Machine Learning in Financial Content Curation
.jpg)
We’ve all typed a search phrase into Google and had it corrected. If you type “nirtkorea decnuliazaiton”, depending on your search history and current events, you might get “north korea denuclearization” as a suggestion. And indeed, that is what you wanted to find.
If we start typing the beginning of a sentence, Google will complete it for us. If we want to know about the weather or directions, we can speak to our smartphones or home assistants and receive understandable answers.
So how do search engines know what you intended to type without asking you again? How do other AI systems understand your question or command and respond (mostly) appropriately? The answer lies in Natural Language Processing (NLP), Deep Learning (DL) and Machine Learning (ML). And a massive amount of data.
What is Natural Language Processing (NLP)?
Sentences are codified pieces of information. The idea (information) resides in one person’s mind, and they want to encode it, transmit it via sound or writing, and eventually have the idea arise in another person’s mind. Human language has evolved into a set of concepts (vocabulary) and a set of rules to properly communicate meaning (grammar). “The dog sees the boy” is different from “the boy sees the dog”. Other languages have other rules and concepts.
NLP is taking these chunks of information and determining what they mean mechanically (by a computer/machine). Computers are not sentient, so we cannot simply give a command and transmit the idea to the computer’s mind. They have no mind. But they may respond as if they do (which is the content of an interesting thought experiment in philosophy, Searle’s Chinese Room).
What is Machine Learning (ML)?
At first glance, it may seem simple to program rules (grammar) into a computer and give it a set of concepts (vocabulary). Unfortunately for hard-coded rules and vocabulary, human language is both malleable and multifaceted. The coder runs into the problem of combinatorial explosion, in which the number of combinations increases rapidly.
Thanks to increases in efficient processing power, it has become more economical to use statistical methods and large amounts of data to make connections. Instead of trying to codify all the rules and concepts of language into lines of code (computer rules), we have now begun to associate words with each other in sentences. It is a bit like a child who hears thousands of sentences over the course of a few years – eventually, it can associate a word with a meaning, recognize the word in sentences, and make new sentences with sets of words it knows. Sentences “feel right” to native speakers of a language because it has been heard so many times, even if the speaker don’t understand the formal rules of grammar. Acceptable variations are known, but unacceptable ones immediately stand out as “unnatural”.
ML is teaching the computer like one teaches a child. We give it hundreds or thousands of data points, telling the algorithms how to associate data. As it records the connections that we tell it, it becomes better at predicting what a new datapoint means (for NLP, it determines what new sentences mean). Once we are confident in its strength, we can feed it millions of data points and transfer all the processing to the machine.
What is Deep Learning (DL)?
Deep learning is really a subset of machine learning. Deep learning uses so-called neural networks to make better predictions. These are layered networks of nodes. Weights are assigned to the nodes, and each layer represents a refinement of the decision. If a new input produces the desired output, the connections contributing to the overall decision are strengthened. The next input might strengthen different connections between different nodes, increasing their respective weights. A false result weakens the connections used to make the decision, lowering their respective weights.
A common use of deep learning and neural networks is in object recognition pictures. As an oversimplified example, say we have a program that determines if the picture contains a cat or a rabbit. The program will first determine outlines by finding rapid gradations in color, which occurs when the picture content changes: a black cat on a white background has a very clear outline, with the background being represented as 255,255,255 in RGB and the cat’s fur as 0,0,0 in RGB.
For the input layer (the first one), we need to tell the computer some values for defining categories. Some possible categories might be “is the tail at least 30% the length of the body?” or “are the ear lengths longer than the head length?” Answering these two questions, one can determine if it is a cat or rabbit without actually seeing the image (and the computer does not “see” the image like a human).
Now, we have to answer those input values and tell the program whether the picture is indeed a cat or a rabbit. On the internal layer (sometimes called hidden layer), the program eventually recognizes rabbits tend to be white and cats tend to have pointy ears. The hidden node “is the object white?” gets a heavy weight for rabbits and the hidden node “are there triangles in the outline?” gets a heavy weight for cats (for the ears). We never design those internal nodes, as they should arise on their own, but they will correspond to some defining characteristic. Now the program can guess if it is a cat or rabbit when it sees a new picture.
Once we are reasonably certain the connection are properly weighted, we can process as many data points as we want and get reasonably accurate results (the simpler the task, the higher the confidence level and accuracy). This is statistics-based, so it is not 100% accurate. But neither are humans when assessing complex and difficult tasks, like diagnosing disease.
This decent, short guide succinctly explains the differences between ML and DL.
What NLP looks like in action
The first step is to build a database of tagged words. For a financial application, we would tag “gold” as a commodity. For an image application, we would probably tag “gold” as a color. Once we have a starting database, we can use it to split up sentences into words, which are individually tagged as their topic. Then a human must manually confirm the tag as correct. This is known as supervised learning.
If the tags are correct, we continue. If the tag is incorrect, the algorithm must be adjusted to the correct tag. In supervised learning, there is a significant amount of manual work.
As the program sees more sentences, it can start to make some connections. Linguistically, these are called collocations. In English, for example, it is extremely common to say “gold prices”. Statistically, it is overwhelmingly likely “gold prices” refers to the financial concept rather than an artistic way of expressing excellent pricing. As the machine sees more articles, it might start to associate “prices rise” and “prices decline” as actionable scenarios. If “gold prices” is tagged a as a financial concept, and “prices rise” is tagged as an event, there comes some understanding from “gold prices rise”.
Now let’s say the final part of the sentence is “on Planet X”, so we have “gold prices rise on Planet X”. “Planet” could be tagged as a location, and on the first try, the program will probably say this is a relevant story (gold prices rise in [location]). The human overseer would have to tag “Planet X” as an irrelevant location (at least for real-world financial news), and in the future, “Planet X” stories will be ignored – though this could lead to interesting problems, like when a scientific discovery of a real Planet X is worthwhile news. The news story might be about the gold price in an online game.
Sometimes machines make their own connections based on patterns. The program may eventually learn in+[location]. It may not have the town of Sarasota, New York in the original database, but it can see “government raises taxes in Sarasota, NY” and it may understand “raise taxes” as an action and can guess (correctly) that “Sarasota, NY” is a location based on “in” and the pattern “unknown word, comma, two-letter US state code”. This is the main goal with ML and NLP: develop the application so that it can make accurate connections on its own.
ML and NLP are not perfect, but they are statistical tools that greatly reduce the number of news stories one must sort through. The algorithm will throw out “Gold Prices Rise on Planet X” and be able to understand that “raising taxes in [unknown location]” is relevant to someone interested in government actions.
Current Usage of NLP
Google uses NLP and DL to guess what meaning you wanted. Personal assistants, like Alexa and Siri, also perform NLP after they parse the audio into text. By matching the audio of your voice against a large audio database, they are able to identify sentences. Subsequently they can parse the sentence into its respective parts and understand your command. Usually the command has been made thousands of times by others, and as the number of instances rises, the better the technology will become.
NLP is also used in chat bots. They take the input (your text), parse it, and attempt to understand your sentence. If they do, they search for the response with the highest probability of being expected, and return it. This probability might be called a relevancy score.
Services like YouTube and Netflix leverage the large amount of data available to them to provide recommendations. You like certain entertainment, and so do others. They find the overlap between the titles others similar to you have liked but that you have yet to experience. It is more likely you will also like this content than a randomly selected title.
Natural Language Understanding (NLU)
One subset of NLP is NLU. This is not simply parsing text and tagging it or some other mechanical action. It requires the program react to a command or inquiry, usually be an untrained person. Importantly, it will try to discover intent or sentiment (positive/negative/neutral) and react appropriately.
The reaction might be to return accurate information. It must also deliver the information in a human-understandable way. If we ask for the weather, we usually don’t want an hour-by-hour breakdown of the temperatures and wind speeds but a simple “warm and breezy”. In context, though, perhaps the former is preferable. Consider the inquiry “I will have a picnic this afternoon. What’s the weather supposed to be?” Here, we may want the breakdown by hour.
NLU, and especially its discovery of sentiment and intent, is concerned with this type of problem. Another NLU example might be the appropriate reaction to “oh, I just spilled my cereal”. Ideally, our robot assistant immediately cleans the floor – or at least asks us if we want it to clean the floor. NLU is the field concerned with this kind of response.
How NLP is used in finance, and business and financial news
In finance, AI and algo-trading is a hot topic. Trading by technical analysis and charting is a prime target for ML, because it can easily be broken down into numbers and statistics. But to become an effective long-term trading method, algo-trading needs to understand why the patterns are arising, and those patterns are often driven by news.
In the markets, psychology plays a major role. Those traders who can assimilate new information into their models early will reap the most reward from the ensuing price swing. That makes understanding and acting on financial and business news a primary concern of major traders and investors, and the obvious choice is to have computers collect, understand, and act than to employ teams of people to do the same thing much more slowly and far more expensively.
Another issue in news is the torrent of information. Thousands of financial and business news stories are published across the world every day. Social media like Twitter serves as a major source of financial news, too. Retail investors are inundated with data and information, and they cannot sort everything themselves. Just collecting all the information themselves would take too long, and unread news stories would accumulate far faster than they could be sorted and filtered by a single person. This is an application with which CityFalcon can help.
Challenges with NLP
Of course ML, DL, and AI are not perfect. They still require a lot of manual labour, especially when training the models. Company names that contain the industry are often missed on the first round. For example, the title “UK Steel shutters coke plant in British Colombia” is easily understood by a human. But a naïve mechanical analysis might see [place][industry][verb][company][asset] in [nationality][place]. It doesn’t know which place is the most relevant (the UK or Colombia).
Unfortunately for our algorithm, Colombia is not part of this article. Neither is Coca Cola. Before the correction stage, the article will incorrectly be tagged relevant for Colombia and Coke. But it is the Canadian province that is important here, and the UK is probably secondary in importance. Moreover, the delineation between Coke and coke is largely related to context. There are 3 uses of the lower-case word, too: the material used in steelmaking, the drug, and a Southern US term for any type of soda.
As the algorithms see more data, they become more accurate. Therein lies another challenge: collecting enough data, and properly tagging it, to produce accurate results. We also need to place it in the proper context. Eventually we want the algorithm to recognize that a title with “steel” and “coke” in it probably means “coke for making steel”. But consider “Coke steels for negative earnings” – here we mean Coca Cola and “steel” means brace or prepare for negative news.
Case Matching as a naïve solution
One solution one might propose for the problem of differentiating Coke (the company) and coke (the drug/steelmaking material) is to case-match. If we have “Coke”, with an uppercase “C”, then we can assume it is the company. Similarly, we can find company names, such as UK Steel by case, because a known (and tagged) place, UK, is directly adjacent to another capitalised word, Steel. The machine can build a rule (perhaps in its inferred hidden layer) that a place next to another capitalised word is likely a company name. And this would probably work – except when news sources publish article titles, they use title case as opposed to sentence case. That means most words are capitalised when they normally would not be. That adds another layer of uncertainty: is the machine looking at a title or a regular sentence.
Title case eliminates the possibility of case-matching, though. Moreover, some publications do not employ title case for their titles. Or maybe they use uppercase only. This is especially true on the internet, where traditional rules of publishing are broken all the time. Even worse, publications are not necessarily consistent across pages within their own website, as different authors have different styles and may have little oversight on formatting.
Statistical and Cultural Bias in Datasets
Another major issue data and training are confounding and hidden variables. This is especially true for complex scenarios like pictures. There may be connections we do not consciously notice as humans but a computer might notice. With neural networks, these connections manifest in the hidden layer, and we don’t even know we have a problem, because we do not know what the hidden network contains.
Biases also creep into the data, either institutionalized and social biases, like racism, or statistical biases. The latter occurs when the training sample is not expansive enough to represent the real world. This is a major concern both in AI and statistics in general. If we could show every possible scenario to the AI, we wouldn’t need the AI in the first place. But finding a sufficiently random sampling is not so easy, partially due to the hidden and confounding variables mentioned above.
The challenges facing NLP are not trivial. NLP is an AI-hard problem and it is speculated, though unknown, that NLU is an AI-complete problem, alluding to the thought we may need to develop general AI before we can confidently achieve human-level NLU. There is plenty of money to be made and perhaps absolute power to be seized upon the completion of general AI, so the stakes are high. We at CityFalcon don’t plan to take over the world, but we do want to help our customers find the most relevant stories. For that, we are employing (non-general) AI for that purpose.
CityFALCON’s NLP services
Our company is focused on delivering relevant news to our customers. To do so, we need to scrape millions of stories from the internet and tag them with their relevance to a personalized profile (i.e., filter them).
Types of Relevancy
Each article is tagged with a relevancy score to a specific topic or to a profile. A news story that mentions Microsoft would get a high relevancy score for the topic “US Tech”. On the other hand, a story that mentions Samsung or Sony might get high scores for “tech” but not “US Tech”. The latter two might get higher scores for “South Korea” and “Japan”, respectively.
The other relevancy score is based on the user profile. Using statistical inference, similarly to Netflix, we can also recommend which articles (and even better, which tags) might interested a reader. We base this off the group the user falls into: if the user belongs to Group 1, then whatever other Group 1 members like will be recommended – assuming the commendation still meets a minimum threshold of relevancy for the user’s particular profile. This recommendation system opens our customers to topics and articles that might interest them, of which they may otherwise remain unaware.
Searching
Our system doesn’t only give recommendations. Our users are also active, and they may want to search for certain stories or topics. Filtering by relevancy prevents overwhelming the user with thousands of potential matches. The most relevant results will be displayed first, and those are usually the ones the user wants. This is exactly what Google does.
An example of how we leverage NLU and ML at CityFALCON
Let’s look at a story from the recent past.
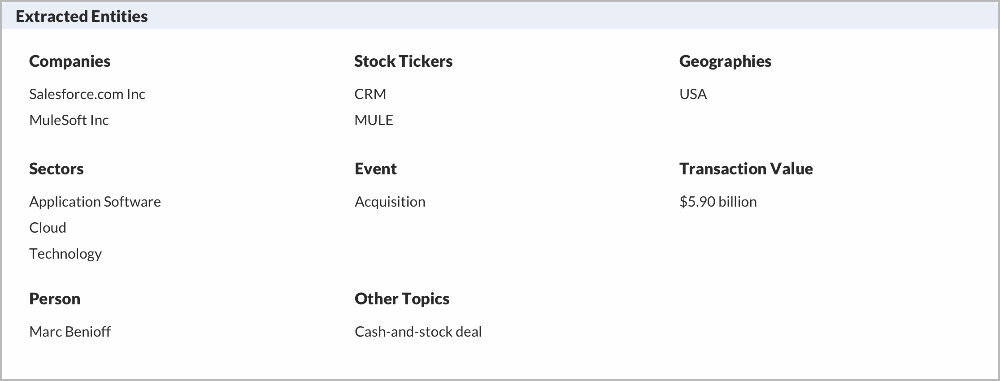
Salesforce to buy MuleSoft for $5.90 billion
Salesforce.com Inc said on Tuesday it would buy U.S. software maker MuleSoft Inc for about $5.90 billion (£4.2 billion) in a cash-and-stock deal, illustrating CEO Marc Benioff’s push to bolster the company’s cloud-based portfolio with new technology.
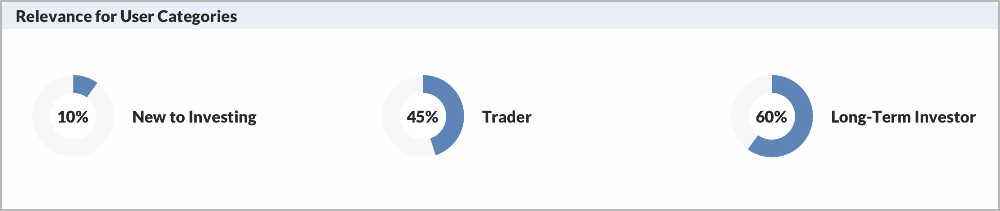
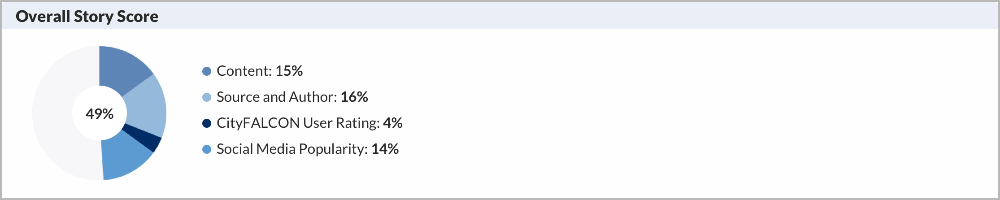
Our system will extract ‘entities’ and relevancy of the story to the entities using NLU and ML. Further, we personalise the content for different user segments and users by leveraging CityFALCON Score.

Contact Us
.jpg)