


Este año ha sido emocionante en términos de nuevos lanzamientos, y el producto CityFALCON realmente está tomando forma con análisis, más fuentes y más servicios en línea en la primera mitad de 2020. Muchos de los servicios y características de la API son realmente muy poderosos, y el esfuerzo de I + D detrás de ellos fue considerable. Por esa razón, la mayoría de las nuevas funciones tienen sus propias publicaciones de blog, para que pueda comprenderlas más a fondo. Esta publicación es simplemente para presentarles lo que hemos logrado en lo que va de año.
Si desea ver lo que hemos hecho del lado del consumidor en la primera mitad de 2020, consulte el Publicación de actualizaciones minoristas de CityFALCON 2020.
Presentaciones de LSE, Companies House, Gazette y más
A principios de este año, comenzamos a atender las presentaciones de la Bolsa de Valores de Londres (LSE) y Companies House en el Reino Unido. Desde entonces, agregamos The Gazette y estamos a punto de agregar presentaciones de la SEC en los Estados Unidos. Ya recibimos los datos y estamos configurados en nuestro entorno de ensayo, pero necesitamos algo más de tiempo para enviar las presentaciones ante la SEC al entorno de producción.
Publicamos un publicación de blog completa sobre nuestro comunicado de presentación. Por ahora, solo están disponibles a través de la API, pero pronto los agregaremos al sitio web y a las aplicaciones móviles.
Extracción de NLU
Otra característica muy valiosa para las empresas es nuestro servicio de extracción de NLU. Una vez más, éste justificó su propia publicación de blog.
Hemos construido el servicio durante gran parte de la vida de CityFALCON y lo usamos internamente para extraer entidades del texto. Por ejemplo, extraemos algorítmicamente Amazon de un titular y márquelo como empresa para ese contenido.
Combinando esto con nuestra base de datos jerárquica, la información resultante puede ser muy esclarecedora. Tenemos el ticker de Amazon, sus números de IRS y SEC, y su sector asociado, industria y estructura de subindustria.
Ahora, las empresas pueden utilizar este servicio y datos estructurados en su propio contenido interno, como notas, chats, correos electrónicos e informes internos. Consulte la publicación del blog anterior para obtener un tratamiento más completo. Proporcionamos extracción de entidades NLU como un servicio independiente para la indexación de contenido interno, por lo que las empresas suscritas no tienen necesidad de comprar otros paquetes API si no los necesitan.
A continuación, se muestra un ejemplo de la respuesta JSON para un mensaje simple enviado entre dos empleados, que proporciona una gran cantidad de información para las empresas.
Respuesta JSON para mensaje informal entre dos empleados"Texto": "cree que Estados Unidos iniciará una investigación contra Facebook",
"Lang": "en",
"Etiquetas": [
{
"Inicio": 14,
"Fin": 16,
"Valor": "EE. UU.",
"Tipo": "ubicación",
"Coincidente": verdadero,
"Entidades": [
{
"Nombre": "Estados Unidos de América",
"Tipo": "geo_regiones",
"Metadatos": {
"países": [
"Estados Unidos de America"
],
"Subcontinentes": [
"América del Norte"
],
"Continentes": [
"Norteamérica"
]
}
}
]
},
{
"Inicio": 51,
"Fin": 59,
"Valor": "Facebook",
"Tipo": "empresa",
"Coincidente": verdadero,
"Entidades": [
{
"Nombre": "Facebook Inc",
"Tipo": "acciones",
"Metadatos": {
"Legal_ids": [
"0201665019_irs-us",
"0001326801_sec-us"
],
"Tickers": [
"FB_US"
],
"Categorías": [
"Redes sociales"
],
"Subindustrias": [
"Servicios e infraestructura de Internet"
],
"Industrias": [
"Servicios de TI"
],
"Sectores": [
"Tecnología",
"Comunicaciones"
]
}
}
]
},
{
"Inicio": 22,
"Fin": 42,
"Valor": "iniciar investigación",
"Tipo": "evento",
"Coincidente": falso
}
]
}
Los tickers y los números legales obtenidos del servicio de NLU se pueden introducir en el servicio de archivos para automatizar muchas tareas. Un posible panel interno que extrae entidades y luego fluye hacia la recuperación de archivos, investigaciones y contenido de noticias puede verse así:
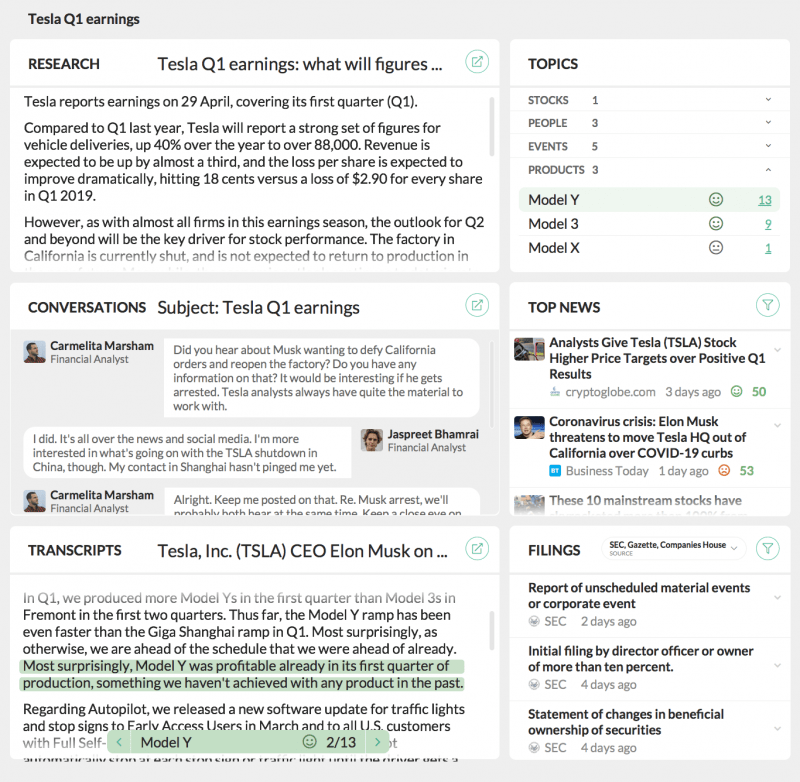
Una posible aplicación interna para ayudar a los empleados en sus investigaciones y operaciones.
Historias similares agrupadas en 16 idiomas
Similar Stories utiliza el aprendizaje automático patentado y avanzado para comparar cada contenido individual que recibimos en busca de similitudes, incluidas noticias, tweets e informes. Cada pieza de contenido se compara con cualquier otra pieza utilizando 512 dimensiones, como autor y ubicación. Por supuesto, con más de 500 dimensiones, algunas pueden parecer combinaciones extrañas y pueden no significar mucho para los humanos, pero las correlaciones que pueden establecer los algoritmos de Big Data pueden revelar algunas similitudes sutiles.
Después de comparar todo el contenido, los grupos se forman en función de la proximidad entre sí en el espacio vectorial de comparación de similitudes. Luego, AI elige al más representativo del grupo (el centroide), y este contenido se marca como la historia principal, que se devuelve como la entrada de nivel superior en JSON. Dentro de cada entrada JSON de nivel superior, el resto del contenido del grupo se incluye en el contenido_imilar campo de esa entrada.
En la web y el móvil, esto permite a los humanos omitir fácilmente contenido repetitivo o, por el contrario, leer varias tomas y ángulos del mismo evento.
En la API, esta configuración puede conducir a un mejor procesamiento de los distintos ángulos. CityFALCON ya agrupó el contenido, por lo que su empresa no necesita investigar y realizar esta complicada tarea de NLU. Ahora puede concentrarse en tomar decisiones con esa información similar en lugar de inmovilizar recursos tratando de construir la tecnología NLU; ya la desarrollamos para usted. Si su aplicación implica entregar contenido a los usuarios finales, puede eliminar todas las historias similares y mostrar solo las entradas JSON principales (es decir, historias únicas), para que se beneficien de la misma reducción en la redundancia.
Además, el algoritmo de similitud funciona en 16 idiomas. Un caso de uso sería capturar los matices para que los equipos bilingües analicen y obtengan información sobre el proceso de pensamiento y los posibles resultados de los eventos, en función de quién escribe qué y cuándo.
Análisis de los sentimientos
Esta es otra característica que es tan valiosa que escribimos un entrada de blog completa sobre análisis de sentimientos.
El análisis de sentimiento es una poderosa analítica que aprovecha la NLU para calificar el contenido en función de lo positivo, negativo o neutral que sea su lenguaje. Nuestros sistemas desglosan el contenido a nivel de cláusula, por lo que incluso una sola oración puede tener más de una puntuación de sentimiento asociada (una para cada cláusula).
Además, al utilizar nuestro servicio de extracción de entidades NLU (internamente, por supuesto), podemos identificar cuál de nuestras 300.000 entidades en nuestra base de datos está asociada con el contenido en cuestión. Luego, creamos puntajes agregados para todas las ubicaciones, personas, empresas, acciones, organizaciones y otros tipos de entidades en la base de datos.
Los grupos agregados, como los sectores (una agregación de todas las empresas constituyentes) también obtienen sus propios puntajes. Los puntajes para los grupos agregados son promedios ponderados, por lo que mientras CityFALCON está en el sector tecnológico junto con Microsoft e IBM, esos dos generalmente tienen mucho más peso que CityFALCON porque atraen mucha más atención de los medios.
Una descripción general simplificada del sistema puede verse así:
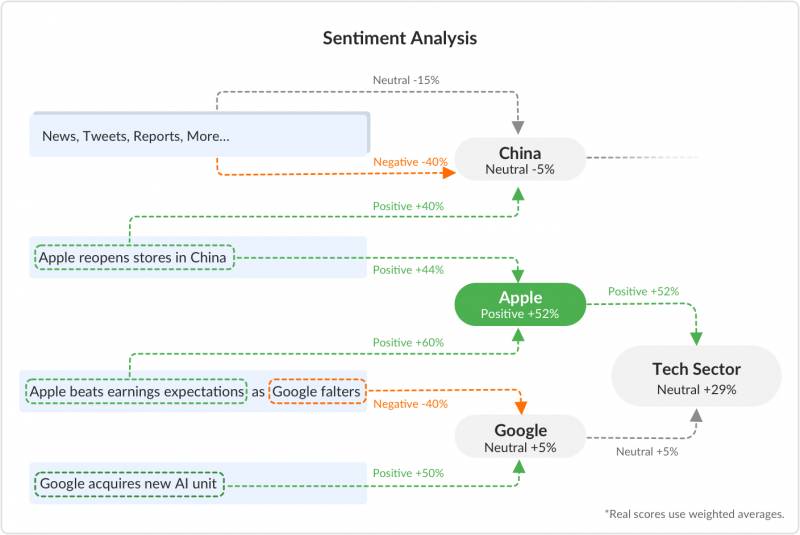
Una descripción general simplificada de las conexiones del análisis de opiniones
A través de la API, estos datos se proporcionan junto con las entidades y el contenido (noticias). Una respuesta JSON con un formato agradable (bastante impreso) con sentimiento puede verse así:
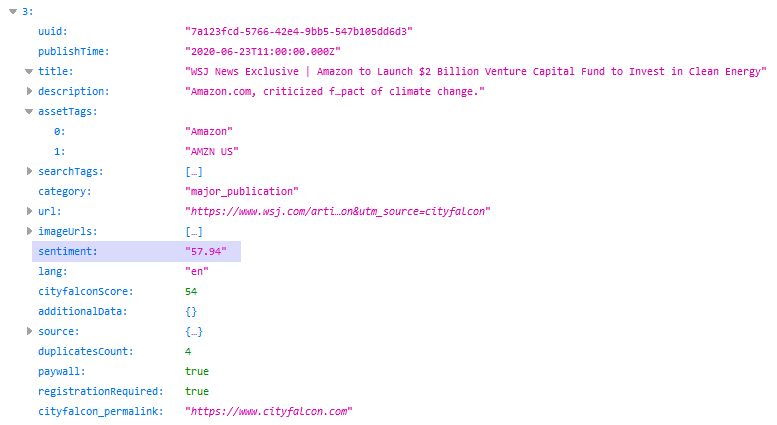
Adición del campo de identificación legal para la búsqueda
Anteriormente, la API solo aceptaba bienes, tickersy full_tickers como campos de entrada para encontrar empresas, personas y otros objetivos de la información solicitada. Ahora, los usuarios de API pueden buscar por legal_id, también. Esto hace que la integración sea más estandarizada y precisa. Además, es más fácil dirigirse a empresas privadas que no tienen tickers. Por ejemplo, Revolut en el Reino Unido es una compañía muy popular de ver, pero no tiene un ticker estándar para identificarla. Con el legal_id campo, ahora los usuarios de API pueden orientar 08804411_ companieshouse-gb para recuperar información sobre Revolut.
Ver el Base de conocimientos para obtener más tutoriales y explicaciones o consulte el documentación para probarlo en la caja de arena.
Acceso a API personal
También hemos abierto la API para uso personal. Vimos el interés de los desarrolladores y las personas que querían crear sus propias aplicaciones financieras y comerciales utilizando nuestros datos, pero no pudieron comprar suscripciones API completas.
Las personas ahora pueden usar la API para realizar hasta 10,000 llamadas por mes y recuperar datos de la historia, el título, la descripción y la puntuación de CityFALCON.
Una suscripción personal comienza desde $20 al mes para usuarios académicos, de atención médica y sin fines de lucro o $40 al mes para todos los demás. Pronto llegará una versión Premium que ofrece más funciones y un límite de llamadas más alto.
Más detalles están en el entrada de blog dedicada al acceso personal a la API.
Partes interesadas y segundo semestre
En lo que va del año, hemos lanzado bastantes funciones importantes para la API, y confiamos en la posición de nuestra empresa para lanzar más en el futuro. Estamos orgullosos de lo que hemos logrado hasta la fecha y estamos encantados de cosechar los frutos de años de I + D en ciencia de datos, infraestructura y curación de datos financieros.
Agregamos constantemente nuevas fuentes de contenido y continuamos con nuestra Proyecto de I + D + i en Malta para ampliar nuestra cobertura de idiomas, tanto desde el punto de vista del contenido como en las aplicaciones de aprendizaje automático. Se avecinan servicios adicionales de aprendizaje automático para datos internos.
Si está interesado en algún servicio de API, Contáctenos para una consulta y demostración. Cuanto mejor conozcamos su caso de uso y su situación, mejor producto podremos ofrecerle.
Deja una respuesta