


Stellen Sie sich das Szenario vor: 75.000 Dokumente und Tonnen von Nachrichten, Recherchen und Chat-Nachrichten, die ohne erkennbares Muster in ihrer Reihenfolge gesichtet, markiert und kategorisiert werden müssen. Sie möchten sie nach Unternehmen und Standort sortieren, aber ohne die Tags auf oberster Ebene, pro Seite und pro Satz scheint die Aufgabe nahezu unmöglich. Ist das 14.198. Dokument ein makroökonomischer Bericht über Nordamerika, China, Tokio oder das Zusammenspiel aller drei? Hat das 47.938. Dokument Diskutieren Sie über Dividenden, Gewinne oder eine neue Produkteinführung? Bezieht sich diese Kunden-E-Mail von vor 6 Monaten auf Google, Alphabet oder GOOG? Schlimmer noch, einige Textsätze können Hunderte von Seiten lang sein und viele verschiedene Themen und wichtige Daten enthalten. Titel, Inhaltsverzeichnisse und Top-Level-Tags können Ihnen nur so viel sagen.
Du könnte Stellen Sie Mitarbeiter ein, die jedes einzelne Dokument, jede E-Mail, jeden Nachrichtenartikel und jede Chat-Nachricht manuell lesen, verstehen und organisieren. Leider verbraucht dies viel Zeit und finanzielle Ressourcen, und mit den täglich wachsenden Chatprotokollen, E-Mails, Nachrichtenartikeln und Berichten ist es möglicherweise sowieso unmöglich, alle Inhalte tatsächlich mit menschlichen Augen und Gedanken zu indizieren. Nachrichten zwischen Mitarbeitern in einer Abteilung könnten sich für die in einer anderen als sehr nützlich erweisen, aber die meisten Unternehmen lassen diese Daten in den Posteingängen der Mitarbeiter verschwinden, wo ihr Hebelpotenzial im Nichts verloren geht.
Eine bessere Lösung ist maschinelles Lernen getrieben Systeme zum Verstehen natürlicher Sprache (NLU), die das automatisieren finden, identifizieren und markieren Prozess, was zu „getaggten Entitäten“ oder „extrahierten Entitäten“ führt. NLU ist ein breiterer Ansatz zur traditionellen Verarbeitung natürlicher Sprache (NLP), bei dem versucht wird, Variationen im Text so zu verstehen, dass sie dieselbe semantische Information (Bedeutung) darstellen. Mit den bis auf die Satzebene extrahierten Entitäten kann man dann alle möglichen durchführen Textanalyse, wie Heat Mapping und Gruppierungen, die zu Erkenntnissen führen. Die Stimmungsanalyse ist eine weitere sehr beliebte Textanalyse, die zum Verständnis großer Korpora (aggregierter Textmengen) verwendet wird.
Bei CityFALCON haben wir gerade ein NLU-Entitätsextraktionssystem und eine Stimmungsanalyse eingeführt, die speziell auf geschäftliche, finanzielle und politische Inhalte in mehreren Sprachen für identifizierte Entitäten und für ganze Dokumente, Nachrichten, Chatprotokolle und E-Mail-Ketten abgestimmt sind.
Das Bedürfnis
Es gibt mehrere Gründe, Produkte, Unternehmen, Personen und andere Themen im Text zu identifizieren und zu markieren. Ein Grund dafür ist, dass Regierungen Vorschriften zur Aufbewahrung von Dokumenten haben und einige Unternehmen über sehr große Mengen an aufbewahrten Dokumenten verfügen, die unorganisiert sind und für weitere Big-Data-Analysen nicht verwendet werden.
Andere Unternehmen bewahren einfach alle ihre Nachrichten und internen Dokumente für spätere Bezugnahme oder spätere Big-Data-Analysen auf. Wenn der Text intern generiert wird, haben sie vielleicht ein paar Tags, aber sie beschreiben den Inhalt darin nicht sehr tiefgehend. Wenn der Text extern erstellt wurde, z. B. Nachrichteninhalte, können Tags unzureichend, ungenau oder nicht vorhanden sein.
In jedem Fall kann aus Tags der obersten Ebene, Titeln von Abschnitten und Abschnittszusammenfassungen nur ein begrenztes Verständnis eines Textes abgeleitet werden. Metadaten existieren in allen Schichten eines Textes, und NLU kann dabei helfen, einzelne Dokumente sowie einen ganzen Korpus besser zu verstehen. Da NLU so granular wie auf Satzebene arbeitet, können Dokumente algorithmisch nach Satz analysiert und die Ausgabe für aussagekräftige Erkenntnisse verarbeitet werden.
Eines der Versprechen von Big Data ist es, Informationsmengen zu verarbeiten, die einzelne Menschen oder Teams von ihnen einfach nicht könnten. Da unser menschlicher Verstand nur so viele Informationen auf einmal speichern kann und die Kommunikation zwischen Menschen dadurch begrenzt ist, wie schnell wir Gedanken durch Sprache übertragen können, ist das Verstehen von drei Millionen Seiten mit Nachrichten, Dokumentationen und E-Mails keine Kunstleistung für einen Menschen oder sogar ein Team. Es ist Sache der Maschinen, in viel handlichere Bits zu destillieren.
NLU und zugehörige Analysen helfen Unternehmen, ihre Inhalte zu organisieren, sie mit Schlüsselwörtern schneller durchsuchbar zu machen, und können Einblicke bieten, die der menschliche Verstand einfach nicht synthetisieren kann (obwohl wir die Ausgabe natürlich verstehen können).
Wo immer es darum geht, große Mengen an Textinformationen in hoher Auflösung zu organisieren, zu kategorisieren und zu verstehen, kann das NLU-System von CityFALCON problemlos Einblicke und abteilungsübergreifende Analysen liefern.
Wie es funktioniert
Auf hoher Ebene zerlegt unsere neu eingeführte API jeden Textsatz in seine einzelnen Sätze und identifiziert dann alle Entitäten in jedem Satz. Nehmen wir zum Beispiel eine aktuelle Überschrift:
Aktien-Futures fallen nach den Gewinnen, Trumps Drohung mit China-Zöllen wegen Pandemie
Welche unsere Systeme wie folgt aufteilen werden:
Aktien = Finanzinstrument
Futures = Finanzinstrument
Ergebnis = Veranstaltung
Trumpf = Person
China = Lage
Tarife = Finanzthema
Pandemie = Finanzthema
Und wenn Sie die vollständige JSON-Antwort sehen möchten, haben wir sie hier für Sie veröffentlicht.
{„Text“: „Aktien-Futures fallen nach den Gewinnen, Trumps Drohung mit China-Zöllen wegen Pandemie“,
„lang“: „en“,
"Stichworte": [
{
„Start“: 0,
„Ende“: 5,
„Wert“: „Aktie“,
„Typ“: „Finanzinstrument“,
„matched“: wahr,
„Einheiten“: [
{
„Name“: „Aktien“,
"Typ": "Thema_Klassen",
„Metadaten“: {}
}
]
},
{
„Start“: 6,
„Ende“: 13,
„Wert“: „Futures“,
„Typ“: „Finanzinstrument“,
„matched“: wahr,
„Einheiten“: [
{
„Name“: „Futures“,
„Typ“: „Finanzthemen“,
„Metadaten“: {}
}
]
},
{
„Start“: 25,
„Ende“: 33,
„Wert“: „Einnahmen“,
„Typ“: „Ereignis“,
„matched“: wahr,
„Einheiten“: [
{
„Name“: „Einnahmen“,
„Art“: „Hauptgeschäfts_und_verwandte_Aktivitäten“,
„Metadaten“: {}
}
]
},
{
„Anfang“: 36,
„Ende“: 43,
„Wert“: „Trumpf“,
„Typ“: „Person“,
„matched“: wahr,
„Einheiten“: [
{
„Name“: „Familie Trump“,
„Typ“: „Menschen“,
„Metadaten“: {}
}
]
},
{
„Anfang“: 55,
„Ende“: 60,
„Wert“: „China“,
„Typ“: „Standort“,
„matched“: wahr,
„Einheiten“: [
{
„Name“: „China“,
„Typ“: „geo_regionen“,
„Metadaten“: {
"Länder": [
"China"
],
„Subkontinente“: [
"Ostasien"
],
„Kontinente“: [
"Asien"
]
}
}
]
},
{
„Start“: 61,
„Ende“: 68,
„Wert“: „Tarife“,
„Typ“: „Finanzthema“,
„matched“: wahr,
„Einheiten“: [
{
„Name“: „Tarife“,
„Typ“: „Finanzthemen“,
„Metadaten“: {}
}
]
},
{
„Start“: 74,
„Ende“: 82,
„Wert“: „Pandemie“,
„Typ“: „Finanzthema“,
„matched“: wahr,
„Einheiten“: [
{
„Name“: „Pandemie“,
„Typ“: „andere_Themen“,
„Metadaten“: {}
}
]
}
]
}
Nehmen Sie weiter die Entität China. Da es in unserer Datenbank „gematcht“ wurde, ist ihm auch eine Hierarchie zugeordnet. Damit ist der Begriff gemeint China können jetzt zurückgegeben werden, wenn jemand auch Ostasien oder Asien durchsucht, was eine viel bessere Indizierung interner Inhalte ermöglicht.
Zusätzlich zu Hierarchien können übereinstimmende Entitäten mehrere Namen zusammen bündeln. Ein solches Beispiel ist der Begriff „Coronavirus“, der in unseren Systemen neben vielen anderen verwandten Wörtern und kurzen Sätzen mit „COVID-19“, „covid19“ und „covid“ abgeglichen wird. Dies ermöglicht es einem Mitarbeiter, einen einzelnen Begriff zu suchen und alle zugehörigen Elemente zu erhalten, selbst wenn eine einfache Textsuche fehlschlagen würde, da die einfache Textsuche COVID-19 wird Erwähnungen von nicht zurückgeben Coronavirus.
Schauen wir uns ein anderes Beispiel an. Dies könnte eine Chat-Nachricht zwischen Mitarbeitern sein:
– Glauben Sie, dass die USA Ermittlungen gegen Facebook einleiten werden?
Auch hier ist das JSON, das von unseren Systemen zurückgegeben wird.
{
„Text“: „Sie denken, die USA werden Ermittlungen gegen Facebook einleiten“,
„lang“: „en“,
"Stichworte": [
{
„Start“: 14,
„Ende“: 16,
„Wert“: „USA“,
„Typ“: „Standort“,
„matched“: wahr,
„Einheiten“: [
{
„Name“: „Vereinigte Staaten von Amerika“,
„Typ“: „geo_regionen“,
„Metadaten“: {
"Länder": [
"Vereinigte Staaten von Amerika"
],
„Subkontinente“: [
„Nordamerika“
],
„Kontinente“: [
"Nordamerika"
]
}
}
]
},
{
„Start“: 51,
„Ende“: 59,
„Wert“: „Facebook“,
„Typ“: „Firma“,
„matched“: wahr,
„Einheiten“: [
{
„Name“: „Facebook Inc“,
„Typ“: „Aktien“,
„Metadaten“: {
„legal_ids“: [
„0201665019_irs-uns“,
„0001326801_sec-us“
],
„Ticker“: [
„FB_US“
],
"Kategorien": [
"Sozialen Medien"
],
„Teilbranchen“: [
„Internetdienste & Infrastruktur“
],
„Branchen“: [
"IT-Service"
],
„Sektoren“: [
"Technologie",
„Kommunikation“
]
}
}
]
},
{
„Start“: 22,
„Ende“: 42,
„Wert“: „Untersuchung starten“,
„Typ“: „Ereignis“,
„übereinstimmend“: falsch
}
]
}
Hier ist „US“ eine übereinstimmende Entität und enthält auch eine Hierarchie. Das konkrete Thema vereinigte Staaten von Amerika wird mit „the US“, „United States“ und „America“ identifizierbar sein und kann auch gefunden werden, wenn jemand Nordamerika durchsucht. Wenn sich ein Mitarbeiter also vage an den Konversationsthread über „Amerika“ erinnert, wird er nicht frustriert sein über die Diskrepanz zwischen seinem Suchbegriff „Amerika“ und dem tatsächlich verwendeten Begriff „USA“. Bei einer normalen Textsuche schlägt der Versuch, die Konversation zu finden, möglicherweise fehl.
Unternehmen sind auch Teil einer Hierarchie in der Wirtschaft, und die Suche nach IT-Diensten stellt sicher, dass „Facebook“ auch in den Ergebnissen enthalten ist. Nicht nur das, sondern weil Facebook ein börsennotiertes Unternehmen ist, werden seine gesetzlichen Identitätsnummern, einschließlich seiner SEC-Kennung und Ticker nach Land, zurückgegeben. Dies könnte mit Unternehmensunterlagen verbunden oder programmgesteuert in einen anderen Algorithmus eingespeist werden, der SEC abruft Einreichungen von CityFALCON oder für Querverweise auf Gerichtsverfahren im US-Gerichtssystem verwendet werden.
Schließlich kann es auch nützlich sein, Aktionen aus einem beliebigen Gesprächs- oder Forschungsbericht herauszusuchen. Die Phrasierung Ermittlungen einleiten wurde von uns abgeholt maschinelles Lernen Systeme als ein Veranstaltung. Diese Daten helfen dabei, das Thema eines Textes zu bestimmen, und ein guter Anwendungsfall wäre, E-Mails mit ihren Ereignissen zu markieren. In diesem Beispiel ist die Veranstaltung war nicht abgeglichen, aber es gibt Zehntausende von Ereignissen auf CityFALCON, die auf die gleiche Weise abgeglichen werden können, wie Standorte und Unternehmen mit zugehörigen Daten abgeglichen werden können.
Da es Maschinen egal ist, ob Sie 1 oder 100.000 Sätze haben, kann derselbe Vorgang unbegrenzt für Korpusse beliebiger Größe wiederholt werden. All dies wird in wenigen Sekunden verarbeitet, wobei unser Algorithmus es auf einer schnellen GPU verarbeitet.
Der Umfang des CityFALCON-Systems
Wir identifizieren 20 Gruppen benutzerdefinierter Entitäten und mehr als 300.000 „benannte Entitäten“-Themen, die finanzspezifisch sind, und fügen eine tiefe Ebene möglicher Analysen für Banken, Regierungen, Hochschulen und andere Benutzer hinzu, die eine Inhaltsanalyse auf der Grundlage von Wirtschafts- und Finanzbegriffen benötigen jenseits von Produkten von Wettbewerbern wie IBM oder Microsoft, deren Systeme auf allgemeine Inhalte ausgelegt sind.
Beispielsweise behandelt ein einzelnes Thema die Idee „Vereinigte Staaten von Amerika“, wobei die zugehörigen Namen wie „US“, „Amerika“ und „USA“ alle als Teil dieses einen Themas angesehen werden, ebenso wie die Metadaten (z Standorte ist dies die geografische Hierarchie). Alle Themen sind mit zugehörigen Informationen und, falls vorhanden, Hierarchien und zugehörigen Namen versehen. Sie reichen von Standorten über Personen bis hin zu Unternehmen und Produkten, und Sie können sie sogar in unserem durchsuchen Verzeichnis wenn du sie alle sehen willst. Über die API können Sie Ihre eigenen Inhalte auf die gleiche Weise indizieren, und diese Fähigkeit ist ein riesiges Reservoir an Organisationskraft.
Mit all diesen Themen- und Entitätsgruppen ist NLU als kognitives Werkzeug verwandelt die Suche von einem Instrument, das eine bereits im Kopf vorhandene Idee festigt, in ein Instrument, das Ideen auf der Grundlage von Konzepten aufbaut. Anstatt nach einem bestimmten Dokument oder einer E-Mail-Kette zu suchen Biotechkönnen Arbeiter nach Branchen-Tags suchen. Vielleicht wird neben der Biotechnologie häufig ein anderer Sektor erwähnt, der als Weg für potenzielle Erkenntnisse dient. Umgekehrt möchte man vielleicht alle Preisbewegungen in einer E-Mail-Kette oder einer Reihe von 15.000 Nachrichten finden, unabhängig von der Richtung und dem verwendeten spezifischen Vokabular (stürmen, stacheln, springen, hochschnellen, hochschießen, etc.).
Zum Zeitpunkt der Veröffentlichung dieses Blogbeitrags sind CityFALCON-Systeme bereit, englische und russische Inhalte zu akzeptieren. Ukrainisch und Spanisch werden diesen Sommer akzeptiert, und andere Sprachen werden hinzugefügt, wenn unsere Systeme durch unsere entwickelt werden F&E-Projekt in Malta im Gange, die Mandarin, Japanisch, Koreanisch, Deutsch, Französisch, Portugiesisch und andere umfasst. Letztendlich werden wir über 90 Sprachen abdecken.
NLU für interne Inhalte
Der Kern von CityFALCON ist NLU: Wir sammeln, aggregieren und verarbeiten Finanznachrichten und -inhalte – verstehen deren Sprache – und liefern sie den Benutzern in Echtzeit. Wir fügen einige Analysen hinzu, wie z. B. eine Relevanzbewertung, Stimmung und einige andere Ideen, die sich in der Entwicklung befinden.
Diese riesige Maschine zum Verstehen hauptsächlich der Finanz- und Wirtschaftssprache funktioniert gut für alle Daten, die wir selbst beziehen. Es funktioniert genauso gut mit Client-Textdaten, sei es firmeneigene Recherchen, Wirtschaftsberichte, Abschriften von Telefongesprächen oder einfache interne Notizen und E-Mails.
Unsere proprietäre NLU-Engine kann von Kunden verwendet werden, um ihre eigenen Inhalte zu indizieren und zu organisieren. Die NLU-Engine wurde von unserem Team aus Finanz- und NLU-Analysten in den letzten drei Jahren anhand von Nachrichtenartikeln, Tweets und behördlichen Einreichungen verfeinert. Jetzt kann diese Befugnis auf interne Finanzinhalte angewendet werden, die Sie indizieren möchten.
Ein potenzielles Mitarbeiterportal kann die folgenden Komponenten aufweisen.
Externe Inhalte
Wir stellen diese Inhalte aus unseren über 5000 Quellen und Twitter bereit. Wir senden Ihnen Nachrichten, Tweets, Finanzberichte und behördliche Einreichungen, einen CityFALCON-Relevanzwert, NLU-Daten zu externen Inhalten und Stimmungsanalysen.
Interner Inhalt
Dies stammt aus allen vom Kunden bereitgestellten Texten, wie interner Korrespondenz, Veröffentlichungen und informellen E-Mails zwischen Abteilungen.
Organisationsübergreifende Inhalte
Einige der zurückgegebenen Tags enthalten nicht nur Namen, sondern auch wichtige Informationen wie die Position in wirtschaftlichen Hierarchien, wie Sektoren und Teilbranchen, sowie rechtliche Informationen wie Firmen-ID-Nummern und Ticker. Diese können Ihre Suche weiter verbessern oder einige Prozesse automatisieren, wie z. B. das Abrufen des neuesten Aktienkurses von einer Börse für Ihre Händler.
Echtzeit-Chat
Mitarbeitergespräche werden getaggt, sobald sie stattfinden, und bieten durchsuchbare Erkenntnisse, z. B. wie oft ein Team einen Sektor oder eine Schlüsselperson während einer Arbeitswoche erwähnt. Dies ermöglicht es Entscheidungsträgern, ansonsten verdeckte, aber nützliche Informationen aufzudecken. Wenn alle über X reden, dann könnte X der nächste große Schritt auf den Märkten sein.
Dies ermöglicht es Mitarbeitern auch, frühere Chat-Threads zu durchsuchen und nach Entität oder Entitätsgruppe statt nach einem bestimmten Schlüsselwort zu suchen, wodurch das Potenzial zum Knüpfen von Verbindungen erweitert wird. Beispielsweise möchte jemand wissen, wie oft ein bestimmter Kollege „Finanzinstrument“ oder „Firma“ erwähnt, unabhängig von den Besonderheiten.
Der Echtzeit-Chat könnte sogar einen Echtzeit-Newsfeed steuern, der sich an das aktuelle Gesprächsthema anpasst.
Visualisierungen
Diese Komponente ermöglicht es, die Struktur und Themen einer Reihe von Texten auf einen Blick zu verstehen, seien es E-Mail-Threads mit Kunden, die Nachrichten der Woche oder Besprechungsprotokolle. Das Layout und Design muss auf Unternehmensseite implementiert werden, aber CityFALCON kann strukturierte NLU-Daten als Grundlage dieser Komponente bereitstellen.
Nur ein Beispiel für eine Ad-hoc-Analyse der Stärke eines Trends könnte in der Stärke der verwendeten Wörter visualisiert werden. Wenn in allen Schlagzeilen „abdriften“, „kämpfen“ und „tiefer treiben“ stehen, wissen Sie, dass die Situation nicht so schlimm ist, als wenn alle „stürzen“, „implodieren“ und „dezimieren“ sagen würden. Durch die Verwendung von CityFALCON NLU wird diese Art der On-the-Fly-Analyse so einfach wie das Betrachten aller Instanzen von a Preis_Bewegung Tag in einer Reihe von Texten.
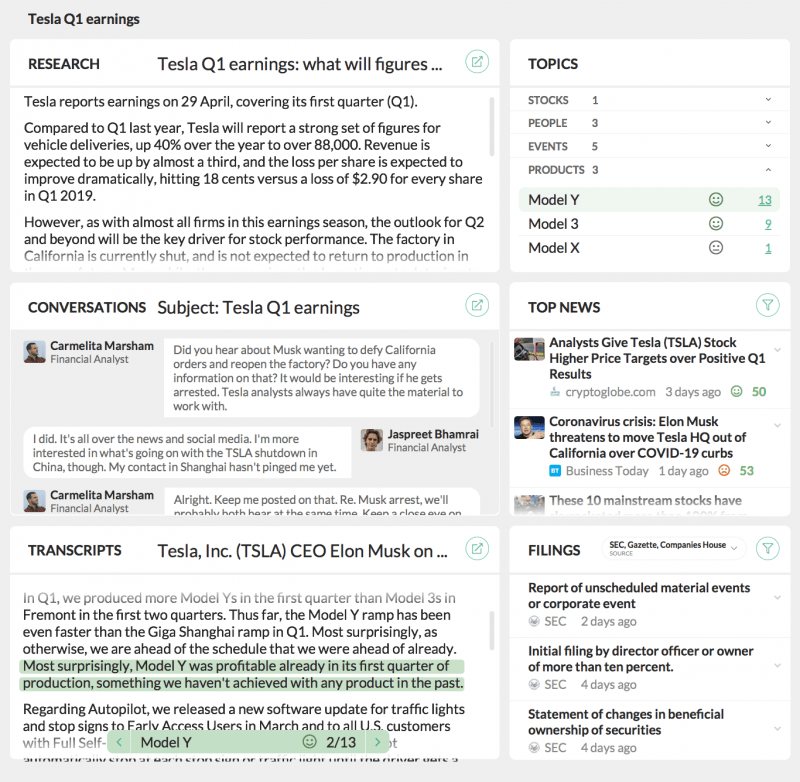
Ein potenzielles Mitarbeiter-Dashboard mit internen und externen Inhalten
Warum für den Service bezahlen?
Einige mögen argumentieren, dass das Erstellen dieser Systeme selbst einfach oder ressourcenarm ist. Einige versuchen möglicherweise, das Tagging und die Organisation an billige Arbeitskräfte im Ausland auszulagern, während andere versuchen, ein paar Entwickler einzustellen, die dies intern tun. Keine dieser Lösungen löst das Problem jedoch angemessen, und ihnen entgeht ein sehr wichtiger Mehrwert.
Erstens kann die schiere Menge an Inhalten möglicherweise nicht von Menschen verarbeitet werden, sodass eine manuelle Verarbeitung nicht anwendbar ist. Außerdem ist es nicht möglich, die manuelle NLU-Extraktion in Echtzeit auf Chats und andere sich ständig ändernde Quellen anzuwenden. Mit maschinellem Lernen und automatisierten Systemen ist dies möglich.
Zweitens dauert der Aufbau und die Implementierung dieser Systeme lange. Die Algorithmen müssen nicht nur trainiert, sondern auch getestet und angepasst werden. Der Aufbau des gesamten Systems kann Jahre dauern, während es möglich ist, die Technologie zu lizenzieren im Augenblick.
Drittens müssen das zugrunde liegende „Verständnis“ und die Struktur des gesamten Apparats angepasst werden, wenn neue Ideen und Konzepte auf die Welt kommen. In Wirtschaft und Politik gibt es ständig neue Personen, Unternehmen, Gesetze und Ereignisse, die es zu verfolgen gilt. Sie bräuchten ein ganzes Team, um all dies zu verfolgen und die Algorithmen entsprechend zu aktualisieren – glücklicherweise erledigt CityFALCON dies bereits für Sie mit unserem mehrsprachigen Finanzanalystenteam.
Können diese Systeme intern erstellt und gewartet werden? Ja. Ihr Bau und die anschließende Wartung werden jedoch schnell teuer und zeitaufwändig, insbesondere in sich schnell entwickelnden Bereichen wie Finanzen, Wirtschaft und Politik. CityFALCON kann die technischen Details behandeln. Sie konzentrieren sich auf den Kunden und das Geschäft.
Letztendlich liegt der Wert in Daten. Mit dem Produkt von CityFALCON kann latenter Wert aus Finanz- und Wirtschaftstextquellen extrahiert und in umsatzgenerierende Unternehmungen wie Handel und Portfoliomanagement geleitet werden. Wir können Ihnen helfen, Ihre Metadaten bis auf die Wörter in Sätzen anzureichern, einzelne Entitäten mit zugehörigen Informationen zu verbinden und webähnliche Verbindungen zwischen allen Teilen Ihres Unternehmens aufzubauen.
Sicherheit und Vertraulichkeit
Da Sicherheit und Vertraulichkeit bei der internen Dokumentation oder der privaten Korrespondenz zwischen Kunden und Mitarbeitern von größter Bedeutung sind, sind Ihre Daten bei unserem System in sicheren Händen.
Um die technischen Details zu vermeiden, wird der gesamte von Ihnen gesendete Text durch einen normalen HTTPS-verschlüsselten Tunnel gesendet, sodass niemand die von Ihnen gesendeten Anfragedaten lesen kann. Dann befinden sich Ihre Daten auf unseren Servern vorübergehend im RAM, während sie verarbeitet werden. Nach der Verarbeitung verschwinden alle Spuren Ihrer Daten aus unserem System. Das bedeutet, dass der Text niemals auf die Festplatte geschrieben oder in unserer Datenbank gespeichert wird.
Wenn jemand unsere Systeme hackt oder ein unseriöser Mitarbeiter versucht, Kundeninformationen zu verkaufen, gibt es keine Daten zu stehlen. Vergangene Inhalte wurden unwiederbringlich gelöscht. Der einzige Nachteil ist, dass Ihre Anfrage nicht zwischengespeichert wird. Wenn Sie also denselben Text erneut extrahieren müssen – vielleicht wurde er versehentlich auf einem internen Computer gelöscht – müssen Sie ihn erneut übertragen. Die Notwendigkeit, ein Dokument erneut zu verarbeiten, ist jedoch ziemlich selten.
Umgekehrt können wir für diejenigen, die die Dinge wirklich lokal halten möchten, eine lokale Systembereitstellung anbieten regelmäßige Aktualisierungen, sodass der gesamte NLU-Prozess am Standort des Clients erfolgen kann, wobei die Daten niemals ihre eigenen Systeme verlassen.
Bequeme Integration
Mit unserer API kann jetzt jedes Unternehmen seine internen Inhalte aus früheren Dokumentationen oder in Echtzeit indizieren. Es ist so einfach wie das Abfragen des API-Endpunkts für die Entitätsextraktion (NLU-Tagging) und die Autorisierung mit dem eindeutigen Schlüssel Ihres Unternehmens. Natürlich müssen Sie Ihr eigenes Dashboard und Ihre eigene Benutzeroberfläche für Ihre eigenen Benutzer erstellen, aber wir kümmern uns um den ganzen schweren Aufwanding in NLU – das ist schließlich unser Service.
Kontaktiere uns um eine Demonstration einzurichten und mögliche Anwendungsfälle, Anrufbeschränkungen und andere Fragen zu besprechen, die Sie möglicherweise haben.
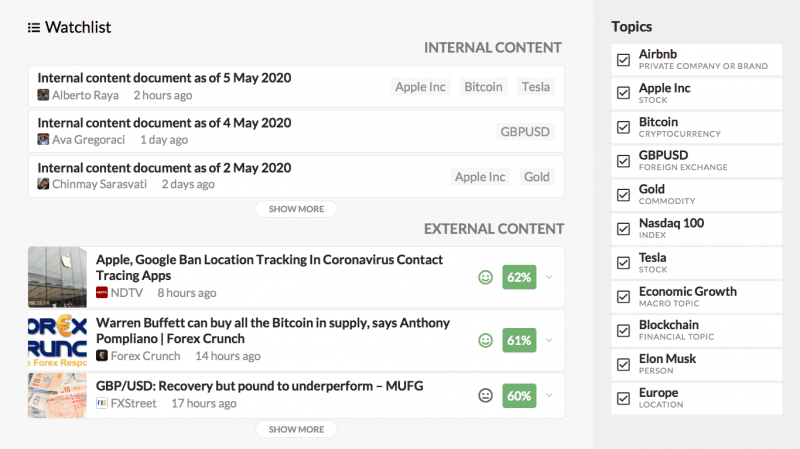
Eine einfachere interne Ansicht mit einer zugehörigen Beobachtungsliste
Schreibe einen Kommentar